
Abstract
The only difference among the images in Fig. 1 is the attention, which varies on one or few attention blocks of the diffuser UNet, then varies during the denoising loops. This work presents AttnMod, to create new unpromptable art styles out of existing diffusion models, and studies the style-creating behavior across different setups.
Approach
Imagine a human artist looking at the generated photo of a diffusion model, and hoping to create a painting out of it. There could be some feature of the object in the photo that the artist wants to emphasize, some color to disperse, some silhouette to twist, or some part of the scene to be materialized. These intentions can be viewed as the modification of the cross attention from the text prompt onto UNet, during the desoising diffusion. Motivated by the idea of creating new art styles mimicking the human artist in putting unusual emphasis on some composure component(s) of the scene, we design the attention modification process, AttnMod, as illustrated in Fig. 2.
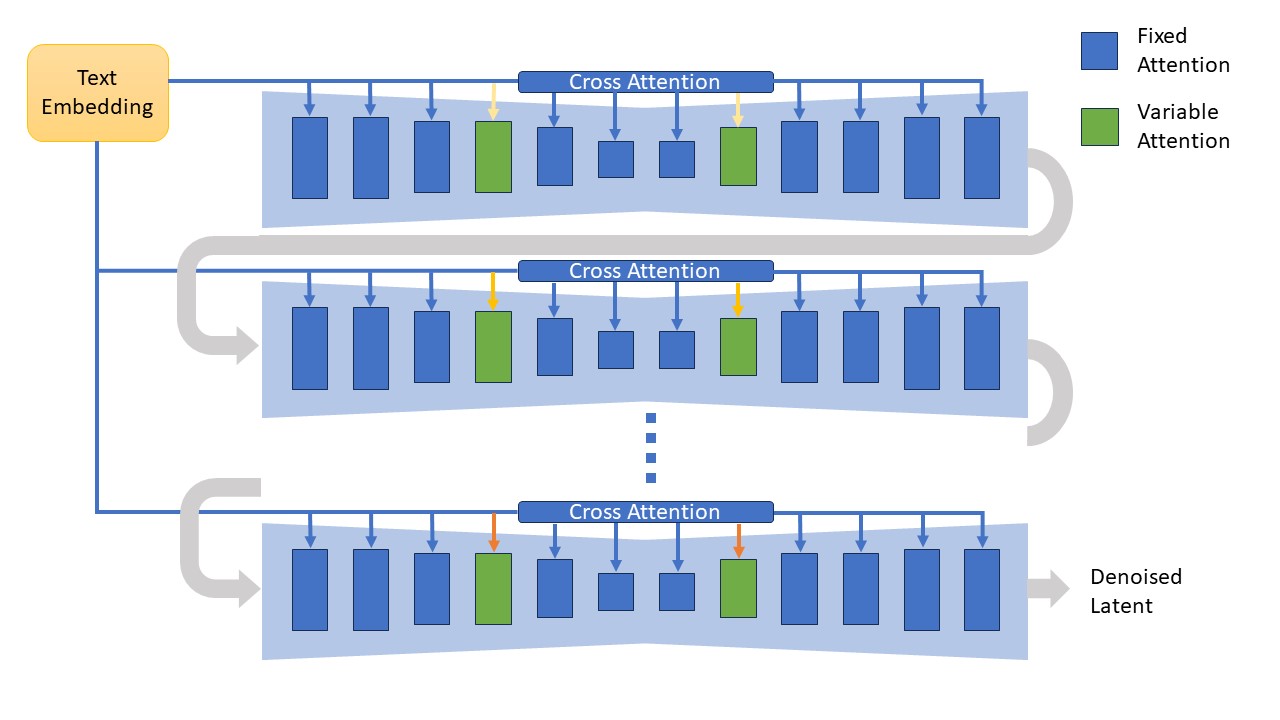
In order to quantify the amount of attention used for conditioning, we introduce the attention multiplier. To better observe how the multiplier impacts the generation, we start with the simplest example. One arbitrary UNet attention block is selected to be modified, while the other blocks are fixed at the default attention which means a 1.0 multiplier. The selected block is then tested with the attention multiplier ranging from -20.0 to 50.0 at the beginning of the denoising diffusion. Within the denoising loop, the attention multiplier is further changed at a constant rate, ranging from -1.0 to 1.0. We select the "up_blocks.1.attentions.1.transformer_blocks.0.attn2.processor", or U1A1A2 for short, to be the modified attention block out of the Stable Diffusion 1.5 (SD1.5). The AttnMod result is as shown in Fig. 3. The original generation, with a starting attention multiplier of 1.0 and change rate of 0.0 per loop, is marked out at the center. The starting multiplier increases toward the right, while the change rate increases toward the bottom.

Seeding
With fixed diffusion input, we check modding on numerous seeds using the constant-rate AttnMod mentioned above, to study how the seed impacts the generation. The output correlates with both the AttnMod setup and the default generation in the leftmost column in Fig. 4, which is again decided by the seed. Therefore, a good AttnMod strategy is to start from a prompt and seed combination that generates an image with good visual layout.
Styling
Experiments are conducted on applying AttnMod over various existing art styles. As shown in Fig. 5, the art styles are prompted in text and cover that of van Gogh, Ukiyo-E, Renoir, Picasso, da Vinci and Dali accordingly as rows. All the images share the same seed 0 and the same diffusion input except the style name, which is part of the text prompt. Images in the leftmost column are default diffusion output.
In Fig 6, we prompted two different styles, Picasso and van Gogh. Tiles at the same location share the same AttnMod setup. An important observation is how the AttnMod setup correlates across different text prompts. Further away from the center when the text prompt loses its influence to a certain degree, the generated artwork gradually diverges from recognizable Picasso or van Gogh styles, instead manifesting as a novel art style that blends and transcends its original influences. A pair of examples are highlighted with yellow borders in Fig 6, which are members of a new style column in Fig 5.


Multi-block Modding
For SD1.5, we pick the two attention blocks within the same transformer block, and mod them synchronously with the same setup. Two of such combinations are visualized in Fig. 7 in rows, which contains the individual AttnMod scans from each of the two attention blocks, then the joined AttnMod scan of them toward the right.


Beyond the two-block attention modding, there are many more combinations, as well as other asynchronous modding methods to be explored. In Fig. 8, we share a slice of possible exploration, where all 32 attention blocks in SD1.5 are opened up for modding and start with 0 attention. In each denoising loop, one block is picked to gain 1.0 attention. The largest attention that a block can have is capped at 1.0. For 40-loop denoising, we show results with two different approaches in picking blocks. The first one is to pick the available block causing the most difference in the output, compared to the previous output, to have 1.0 attention gain. This approach attempts to include as much as the text "conditioning" within the strategy boundaries. On the other hand, the second approach avoids the influence as much as possible. Both approaches generate new art styles, so do further tweaking this strategy or devising more sophisticated strategies.

SDXL
Compared to the 32 attention blocks in SD1.5, SDXL has 140 blocks. In Fig. 9, we only show the AttnMod scan on two of them.

Bibtex
@misc{su2024attnmod,
title={AttnMod: Attention-Based New Art Styles},
author={Shih-Chieh Su},
year={2024},
eprint={2409.10028},
archivePrefix={arXiv},
primaryClass={cs.CV}
}